Research Publications
Advancing Natural Language Processing, Computer Vision, and Machine Learning
2025
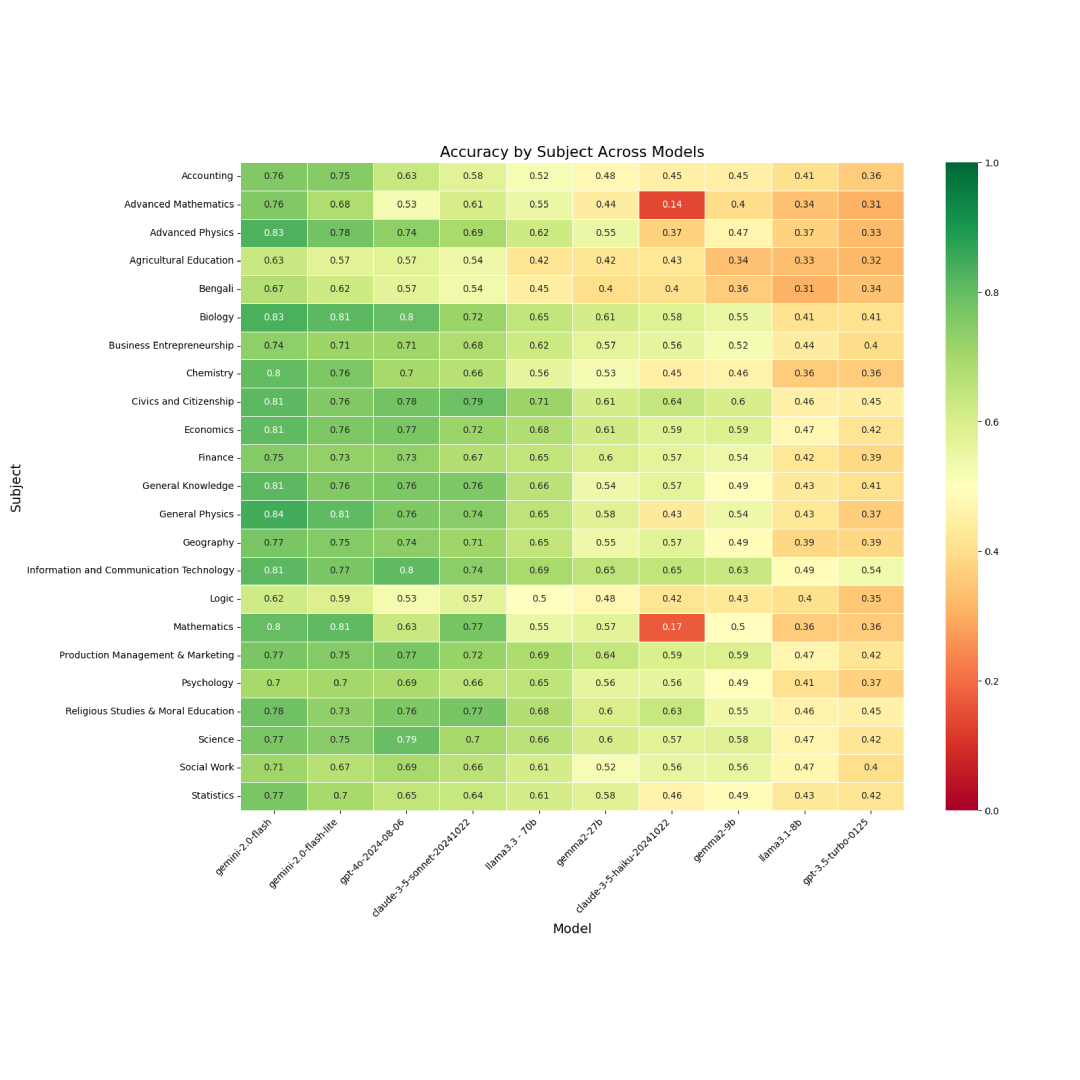
BnMMLU: Measuring Massive Multitask Language Understanding in Bengali
Saman Sarker Joy, S. Shatabda
arXiv preprint
We introduce BnMMLU, a 138,949-question Bengali benchmark spanning 23 domains across science, humanities, math, and general knowledge. We evaluate 10 proprietary and open LLMs and analyze factual knowledge, procedural application, and reasoning skills, revealing notable gaps in reasoning. We release the dataset and code to support future Bengali LLM research.

Eyes on the Image: Gaze Supervised Multimodal Learning for Chest X-ray Diagnosis and Report Generation
T. I. Riju, S. Anwar, Saman Sarker Joy, F. Sadeque, S. Shatabda
arXiv preprint
We present a gaze-supervised multimodal pipeline for chest X-ray diagnosis and region-aware report generation. Radiologist fixations guide a contrastive learner, improving classification (F1 0.597→0.631, AUC 0.821→0.849) and attention alignment. A modular prompting stage then produces region-aligned sentences, improving clinical keyword recall and ROUGE.
2024
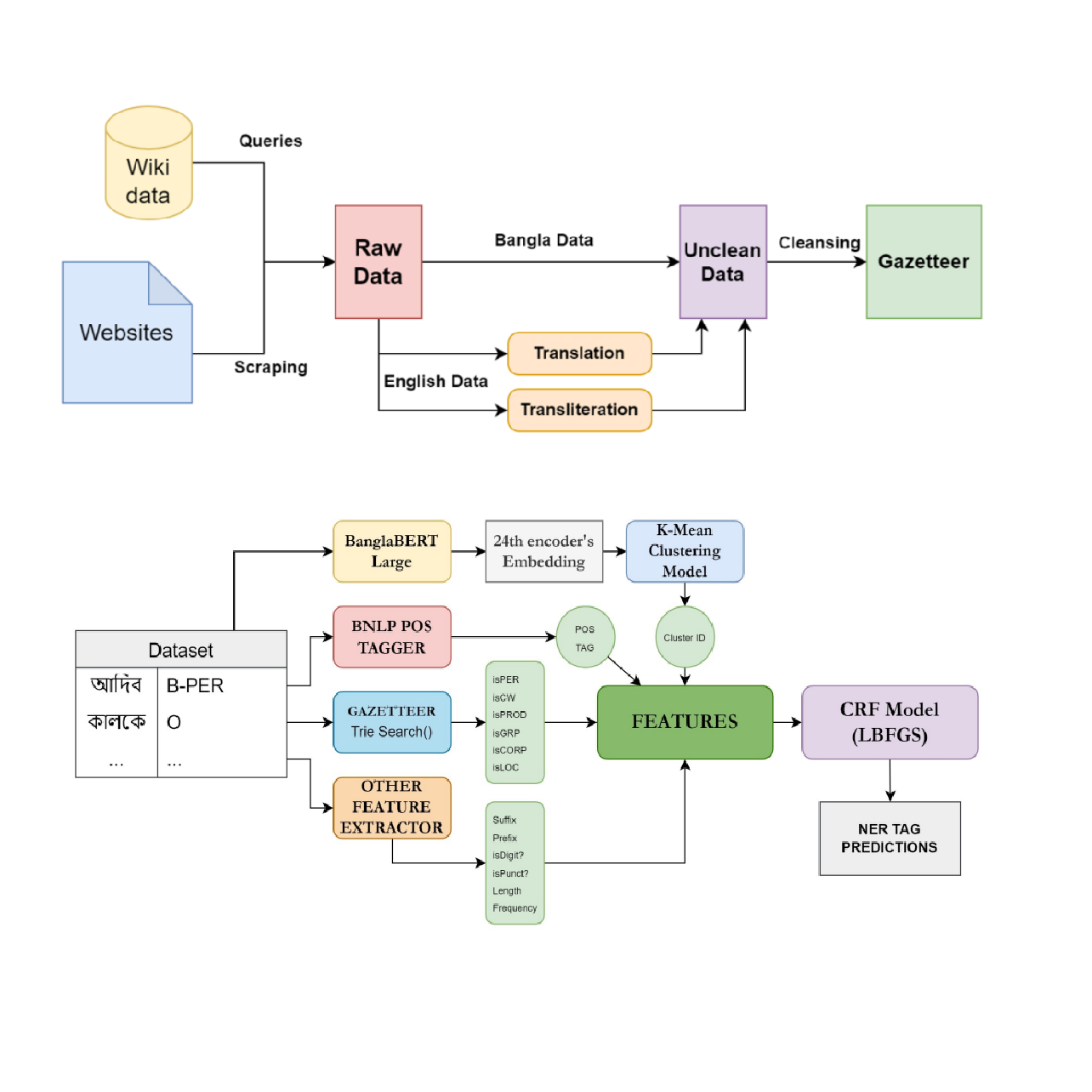
Gazetteer-Enhanced Bangla Named Entity Recognition with BanglaBERT Semantic Embeddings K-Means-Infused CRF Model
N. Farhan*, Saman Sarker Joy*, T. B. Mannan and F. Sadeque
arXiv preprint
We combine Gazetteers, BanglaBERT embeddings, and a K-Means–infused CRF for Bangla NER. The hybrid design strengthens entity boundary decisions and reduces label noise. On standard Bangla NER datasets, the approach achieves state-of-the-art results and strong generalization.
2023
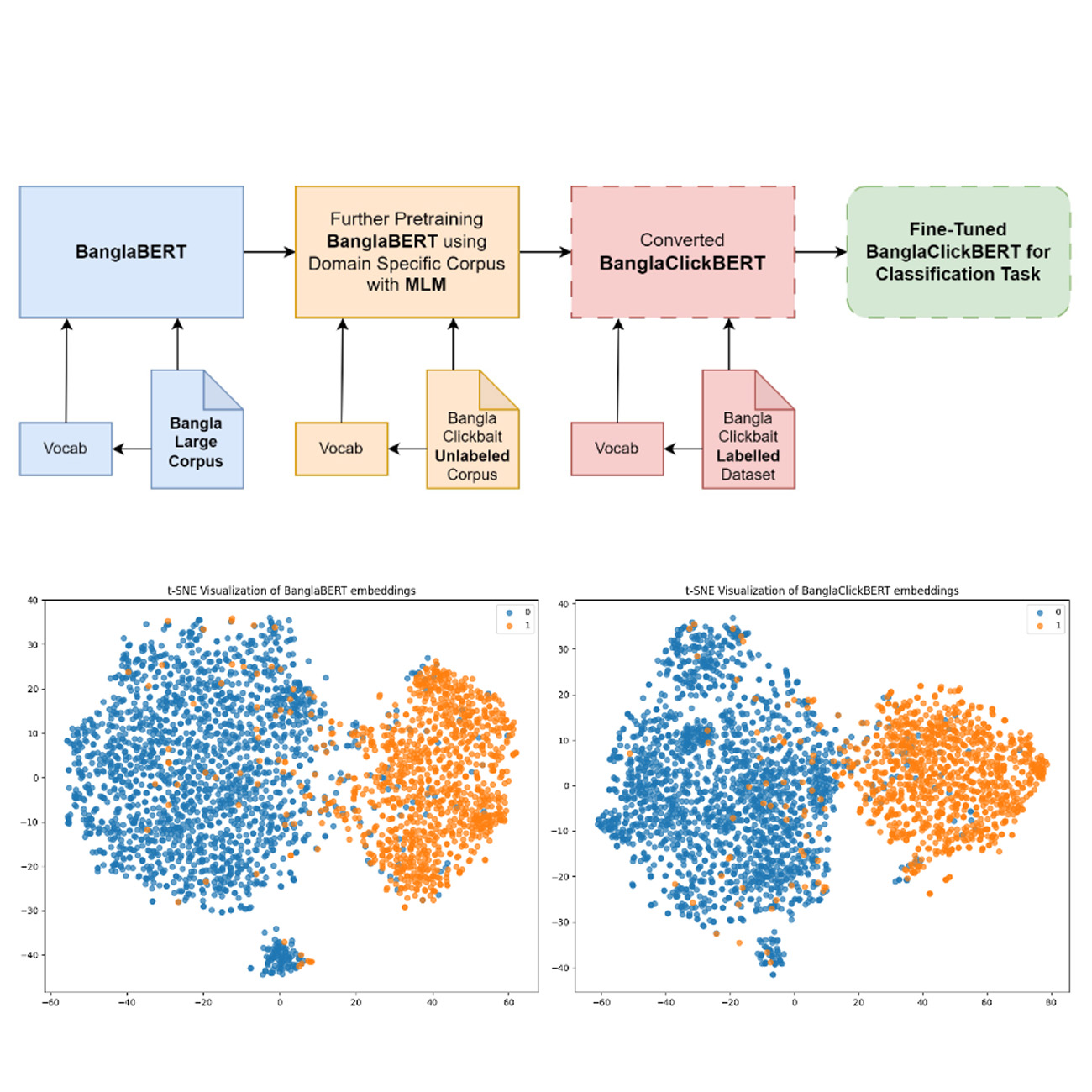
BanglaClickBERT: Bangla Clickbait Detection from News Headlines using Domain Adaptive BanglaBERT and MLP Techniques
Saman Sarker Joy, T. D. Aishi and A. A. Rasel
Proceedings of the 21st Annual Workshop of the Australasian Language Technology Association
We detect Bangla clickbait using a domain-adaptive BanglaBERT with an MLP classifier. Domain adaptation improves headline semantics, while lightweight heads stabilize optimization. The model consistently outperforms prior methods on benchmark datasets.
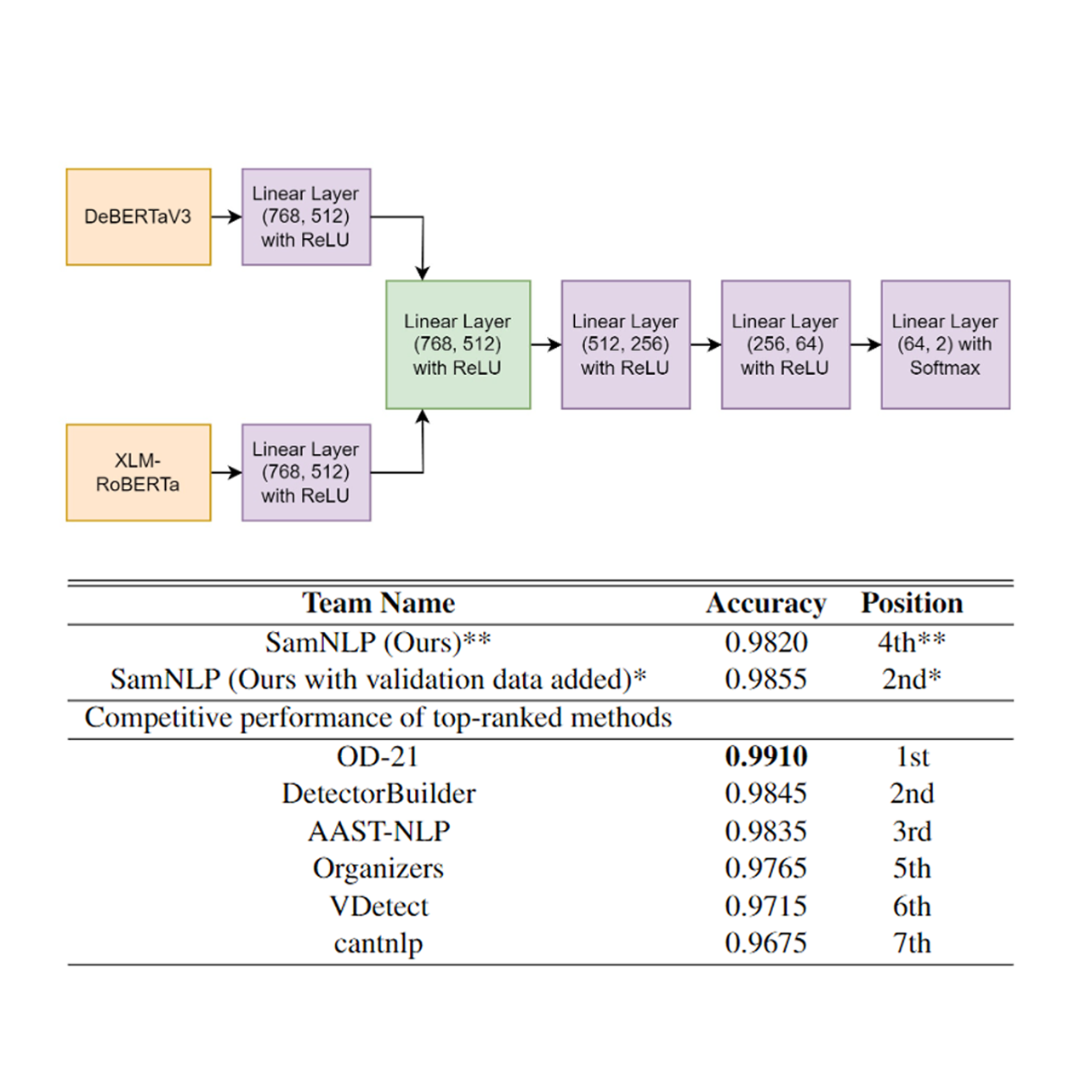
Feature-Level Ensemble Learning for Robust Synthetic Text Detection with DeBERTaV3 and XLM-RoBERTa
Saman Sarker Joy, T. D. Aishi
Proceedings of the 21st Annual Workshop of the Australasian Language Technology Association
We detect synthetic text via a feature-level ensemble of DeBERTaV3 and XLM-RoBERTa. Complementary representations boost cross-domain and cross-lingual robustness. The ensemble improves detection performance over strong single-model baselines.